新文章发布在微信公众号「运维网咖社」,欢迎关注

2021-01-06 259℃ 矢量比特 26 喜欢
")







热度 (10792) 337 喜欢
1 大型系统的运维要从哪些方面抓起——全面质量管理热度 (10133) 168 喜欢
2 玩儿透ELK体系大型日志分析集群方案设计.搭建.调优.管理热度 (4654) 39 喜欢
3 基于etcd+confd对监控prometheus的服务注册发现热度 (4245) 60 喜欢
4 微服务架构下业务单机QPS跑不上去应从哪些角度分析热度 (3769) 96 喜欢
5 透过大型门户平台保障诠释"应用运维架构"方法论热度 (3743) 50 喜欢
6 kafka与zookeeper管理之kafka-manager踩坑小记热度 (3711) 33 喜欢
7 小米小爱同学背后的健康稳定是如何通过技术保障的?(SRE视角)热度 (3524) 39 喜欢
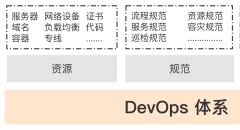
8 如何从零思考设计你的DevOps运维服务体系? 2021-01-06 259℃ 矢量比特 26 喜欢
2020-08-16 3524℃ 矢量比特 39 喜欢
2020-07-10 479℃ 矢量比特 15 喜欢
2020-06-21 3711℃ 矢量比特 33 喜欢
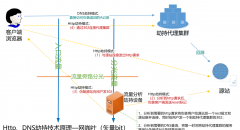
2020-04-20 452℃ 矢量比特 21 喜欢
2020-04-05 622℃ 矢量比特 14 喜欢

2020-04-05 3021℃ 矢量比特 44 喜欢
2020-04-05 10792℃ 矢量比特 337 喜欢

2020-03-05 2455℃ 矢量比特 69 喜欢
2019-05-13 1401℃ 矢量比特 20 喜欢