开题:万事皆有道,运维亦然,寻到规律,事办功倍,今天跟大家分享下应用运维如何高效的接手一个新业务。 很多同学接到新业务时是茫然的,不知道从哪下手,被动等待交接者交接的东
前记:老司机是老东家新浪的同事封的,那是一只团结有战斗力的team,在新浪内部做了很多的技术创新和尝试,我以在这个团队待过为傲,还是很怀念揭老板带我们烟花三月下扬州团建的日子,有几个同学还是第一次坐火车出北京,我们在火车上吹着牛逼喝着酒,冯老板、揭老板、备爷、马老板、老年人杨哥、运气王雄飞、剑平、洪磊、大神鹏哥、二货滕贺、志武、王超、恒俊、妹子王金.......

开题:万事皆有道,运维亦然,寻到规律,事办功倍,今天跟大家分享下应用运维如何高效的接手一个新业务。
很多同学接到新业务时是茫然的,不知道从哪下手,被动等待交接者交接的东西,交接完毕后依然迷糊,究其本质没有框架和思维结构的接手是茫然的,很多时候就像黑瞎子掰玉米,最后脑袋里剩的就是最后那个“玉米”和一些碎片化信息,其实完全可以主动点,把握结构和思路,一般而言,拿到一个新业务,要达到能拎起来的地步是要下功夫的,但并不是下了功夫就能拎起来,当中牵涉到一个道,一般而言,要从下面几个事情做起。
一、知其用
不要以为这个问题太基础,很多同学做运维,都不知道自己的产品从用户角度看是做什么用的。
知其用就是知道自己的业务叫什么?做什么用的?解决了什么问题?产品的用户是谁?在整个公司的产品生态里是什么位置?只有知道了这些,才知道自己产品的分量,知道什么用户报障是跟自己的产品有关系,知道自己的产品有故障时会造成什么影响。
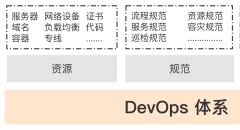
二、摸家底——1图、1表、1账本
知其用后就要摸家底了,此事儿极其重要,摸家底切忌不可眉毛胡子一把抓,摸之前最重要的是要有模块化思维,任何一个雇专职运维的产品都不会是个很简单的产品,而一个有规模的产品定是经过微服务化设计的多模块产品,这时候一定要先把产品的模块理清楚,找出独立的模块单元,参考“一、知其用”的方法进行简单了解,然后弄清楚模块间的骨干逻辑,并画出模块间调用的骨干逻辑图,这里切忌不要追求细,要懂得“舍”,刚开始就求细的结局就是劳人烦己,容易被细节带到沟里,即使有现成画好的,也要自己画一个“骨干模块逻辑鸟瞰”,细致的逻辑等工作过程中慢慢学吧,跟着开发一起迭代升级进步。
这里有个思维洁癖的问题,一定不要想着把每个点都能一步到位弄清楚,二八原则,抓大放小,先把那80%的重点弄明白即可,后续留着慢慢掰扯,我们有这个追求完美的心是不错的,但现实中由于人员流动、老代码、老模块等原因,确实没有同学能给你说的十全十美,不能因为追求完美这个事儿耗费过大精力,导致其它事情停滞不动。
好了到此为止,我们有了一张图——“骨干模块逻辑鸟瞰”图,下一步就是要给这张图添枝加叶了,真正的摸家底可以开始了,这个过程会形成一张表,这张表就是产品分模块的资源鸟瞰,从我目前经验看,主要有这么3个维度的资源:服务器、域名、lb,理的过程中把对应模块的容量、开发人员做相应了解,到此你就有一个产品的工具箱了,例如下面一个简单的服务器鸟瞰表:

摸家底的过程中会遇到各种历史包袱,比如前辈留下的坑、老业务、老代码,这个时候不要怕,也不要发牢骚,哪个公司和产品都会有这个问题,我们就是来解决这些问题的,这里要遵循一个白名单原则,先把确定的健康的资源标注理出来,正向循环,把剩下的七零八碎的放在一起慢慢收拾,因为这种收拾往往是擦屁股的活儿,非一己之力就能完成,但要把这些七零八碎的一一当做账单记下来,形成一个“账本”,这个账本的内容视紧急程度和产品团队工作量饱和情况进行消化,一定记住这些事情是做一件少一件的事情,不可贪全,目前互联网公司产品迭代的压力都很大,而且还有个填老坑老板觉得算不上什么大贡献的恶习,开发同学做新业务的动力和优先级一定比填老坑的大,要相互理解。
好了到此为止我们有了一份家底资料,内容包括1图、1表、1账本,产品所有资源鸟瞰都在这里,做起什么和聊什么相对能插上话了,通过摸家底,也知道了很多业务上的事情,可谓收货颇多。
三、看调用
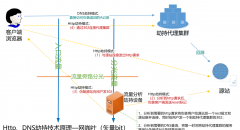
看调用在摸家底理模块的时候有所接触,不过角度和出发点不一样,摸家底时是为了记忆,而看调用是为了深入理解产品、分析产品问题,当然最后的调用图可以是“骨干模块逻辑鸟瞰”图修饰更改而成,形成一张统一的“业务架构图”,其中“子模块的详细架构图”也可以画,视情况而定,另外在一张图里不要事无巨细的加内容,要有主题懂得取舍,因为太简单了没营养,太复杂了画完后自己都不想看,图的维护也是要有成本的。
看调用要从用户的角度出发,看请求的流转,有两个层次1是业务模块逻辑间流转,2是基础系统层面流转,简单解释就是服务器、vip、域名等这些资源有了,看调用是把这些资源串起来形成关系,如果不理调用,就像电影大饭局里的大师言“五行有了,但五行缺串”。
在理调用过程中的同时,要干3件事情,1是弄清每个模块提供服务的方式,通过域名还是deamon等并做好记录,2是要弄清每个点的调用方法,比如说是轮训、还是哈希......3是要记录每个模块依赖的外部产品资源,比如说redis、db等。这些在未来遇到问题分析问题时肯定会派上用场,而且很重要,一个服务一般而言要建议开发做成面向服务的、无状态的、无单点的,从运维的角度来说这个系统才能健壮运行,否则后期麻烦事儿会很多。
四、抓告警
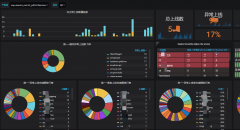
在围绕运维数据的工作中,告警是最重要的事情,告警意味着问题和故障,告警本身是对监控的一个收敛,监控可以慢慢理,但告警一定要在这个时候弄清楚,告警里也是分级的,先把业务的生死告警理清楚,跟交接的同学问清每个模块都有哪些不得不处理的告警,影响面有多大,当然如果上任做的好,会有梳理好的dashboard监控图,收到告警后可以通过dashboard看到故障点在哪里。
梳理出每个模块对应的生死告警项后,做好记录,并留心日常的业务告警,形成1张表,其实以后上手了,这个表是打开频次最少的。
五、管变更
问题和故障都不是无缘无故突然冒出来的,很多是因为某一个变化造成的,牵涉到产品本身最大的两个变更就是代码变更和配置变更,这两个事情一定要管理起来,如果暂时做不到管理起来起码要监控起来,每次变更都要做变更通知,最简单的方式建个QQ群,这样在发生告警的瞬间就可以迅速的知道是不是因为某个变更造成的,干到现在,觉得想从测试和灰度这两点把变更类故障彻底解决掉是个天真的想法,人性使然,工程师总有各种理由不去测试和灰度,而有些模块的业务结构也确实无法支持灰度,仅测试环境测试不放在生产环境灰度很多问题是看不见的,更进一步说有些问题即使灰度了也不见得马上就会出现。
说明一点,关于解决问题可以从技术和制度两个手段出发,对于人这个群体,制度相比技术其实是不靠谱的,就像上面提到的测试和灰度,人性使然,总有各种理由不遵守制度,所以能用技术解决的问题一定用技术解决,技术一时半会解决不了的再用制度约束,制度的建立很多时候是为技术争取时间,作为运维要灵活使用这两个手段,有的时候既要有技术也要有制度,例如我现在做的一个变更监控(中间多谢李博同学的支持)如下:

六、做导航
导航的本质是一个思维导图,可以快速的找到你要的东西,在新浪做时效果很好,所以也拿到了新东家。申请一个简单好记的域名,把你所有相关的事情都画到上面,推荐一个工具grafana,既漂亮又实用,监控UI的不二之选,支持的数据源也特别丰富,例如目前的一个导航如下,可以看出需要做的事情还是很多的,同时也可以把公司的系统都画上去,系统太多如果不集中一下太痛苦了,好了就分享到这儿了,希望对现在的你有所帮助。


 |
社长"矢量比特",曾就职中软、新浪,现任职小米,致力于DevOps运维体系的探索和运维技术的研究实践. |